
개요
LLM 기술의 발전과 함께, ChatGPT와 같은 언어 생성 모델은 사용자와 자연스러운 대화를 나눌 수 있는 능력을 갖추고 있다. 하지만 이러한 모델은 때로는 종종 의미 없거나 입력과 상관없는 텍스트를 생성하곤 한다.

이 현상은 "hallucination"이라고 부르며, 사용자가 질문한 내용과 관련 없는 정보를 생성하는 문제를 나타낸다.
이 "hallucination" 문제를 극복하고 LLM의 성능을 향상시키기 위해 RAG(Retrieval-Augmented Generation) 기술을 도입할 수 있다. RAG를 통해 특정 도메인에 대한 정보를 전달하면 해당 도메인에 대해 전문적인 LLM이 될 수 있다.
본 프로젝트에서는 야구에 대한 정보를 전달하여 야구와 관련된 질문에 더 정확하고 유용한 답변을 생성하는 것이 목표이다. 데이터는 이전 프로젝트였던 KBO 타자 대시보드 시각화 프로젝트에서 크롤링한 데이터를 활용하였다.
핵심 기술 소개
1. RAG
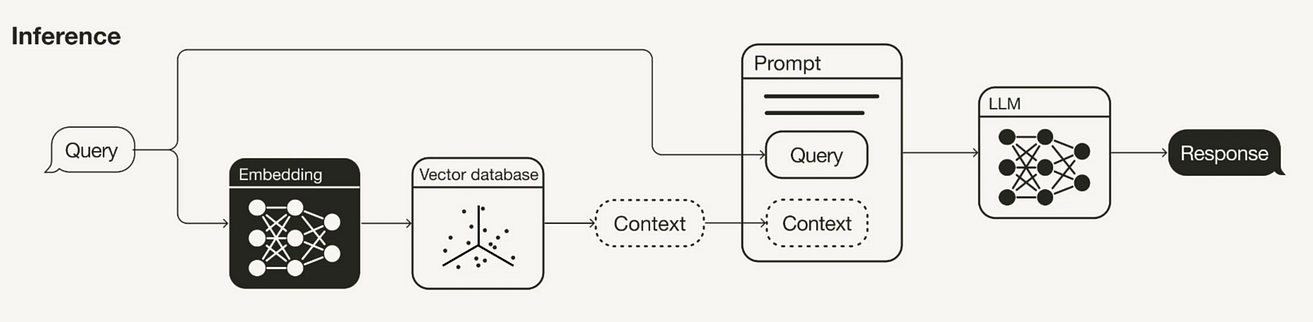
RAG(Retrieval-Augmented Generation)는 실시간 데이터와 같은 추가 데이터로 LLM의 지식을 보완하는 기술이다.
LLM은 다양한 주제에 대해 추론할 수 있지만, LLM의 지식은 학습된 특정 시점까지의 공개 데이터에 제한된다. 따라서 모델이 훈련된 특정 날짜 이후의 새로운 데이터에 대한 추론을 수행하고 싶다면 모델의 지식을 해당 정보로 보강을 해야 한다. 이 정보를 모델 프롬프트에 가져와 삽입하는 과정을 RAG(Retrieval-Augmented Generation)라고 한다.
예를 들어, 2023시즌 전준우의 성적에 대한 질문에 대답할 때, RAG는 해당 데이터를 가져와 이에 기반한 정확한 응답을 생성할 수 있게 된다.
2. LangChain
LangChain은 언어 모델을 기반으로 하는 응용 프로그램을 개발하기 위한 프레임워크이다.
다양한 기능을 지원하며 특히, RAG를 LangChain으로 구성하고자 한다.
개발 환경
개발 환경은 코랩을 활용하였습니다. 다만, GPU가 필요없어서 로컬로 돌려도 충분합니다.
코드 설명
Import Library
!pip install langchain google-cloud-aiplatform qdrant-client cohere wikipedia -q- langchain: RAG 구성 및 LLM 어플리케이션 구성을 위한 프레임워크
- google-cloud-aiplatform: Vertex AI를 활용하기 위해 임포트
- qdrant-client: qdrant를 데이터베이스로 활용
- cohere: 데이터베이스 저장시 임베딩시 활용
- wikipedia: ReAct구성 시 인물 검색을 위해 임포트
Google Authentication
from google.colab import auth
auth.authenticate_user()- 노트북이 계정에 엑세스할 수 있도록 허용 (코랩에서만 필요한 걸로 알고 있음.)
from getpass import getpass
project_id = getpass()- GCP 상에서 진행할 프로젝트 ID 입력하기
import vertexai
import google.auth
from vertexai.preview.language_models import TextGenerationModel
creds, _ = google.auth.default(quota_project_id=project_id)
vertexai.init(project=project_id, credentials=creds)- google로부터 자격 증명을 얻어와서, vertex ai 초기화 진행
Load LLM
from langchain.llms import VertexAI
llm = VertexAI(model_name="text-bison", max_output_tokens=1024, temperature=0.3)- 텍스트 전용 모델인 "text-bison" 모델을 로드한다.
- max_output_tokens: 출력되는 토큰의 최대 크기를 설정한다.
- temperature: 낮을수록 확률이 높은 토큰, 높을수록 토큰의 무작위성이 증가
Basic Example
print(llm("한국의 수도는?"))서울
print(llm("이대호는 누구야?")) 이대호(1982년 6월 11일 ~ )는 대한민국의 야구 선수로, KBO 리그 삼성 라이온즈의 포수이다.
이대호는 2001년 신인 드래프트에서 1차 지명을 받아 삼성 라이온즈에 입단했다. 2003년에 데뷔한 이대호는 2006년에 첫 골든 글러브를 수상했고, 2009년에는 한국 프로 야구 역사상 최초로 포수로서 홈런왕을 차지했다. 이대호는 2010년에 메이저 리그 시애틀 매리너스로 이적했지만, 2012년에 삼성 라이온즈로 복귀했다.
이대호는 2013년에 KBO 리그 MVP를 수상했고, 2014년에는 한국 프로 야구 역사상 최초로 포수로서 타점왕을 차지했다. 이대호는 2015년에 일본 프로 야구 소프트뱅크 호크스로 이적했지만, 2017년에 삼성 라이온즈로 복귀했다.
이대호는 2018년에 KBO 리그 홈런왕을 차지했고, 2019년에는 한국 프로 야구 역사상 최초로 포수로서 타율왕을 차지했다. 이대호는 2020년에 삼성 라이온즈와 재계약을 맺었고, 현재까지도 삼성 라이온즈에서 활약하고 있다.
이대호는 한국 프로 야구 역사상 최고의 포수 중 한 명으로 평가받고 있다. 이대호는 강한 타격력과 수비력을 겸비하고 있으며, 리더십도 뛰어나다. 이대호는 한국 프로 야구에서 많은 기록을 수립했고, 한국 프로 야구의 발전에 크게 기여했다.
print(llm("손아섭의 2014년 홈런 개수는?")) 손아섭은 2014년에 은퇴했기 때문에 2014년에 홈런을 기록하지 않았습니다.
확실히 한국의 수도와 같은 간단한 상식은 잘 대답하지만, 이대호나 손아섭에 대해서는 잘못된 정보를 생산하여 전달하고 있다. (강제 은퇴 무엇...)
Load CSV
import pandas as pd
df = pd.read_csv("./hitter_record_1982_to_2023_cleaned(ver.2).csv")- 데이터프레임 형태로 시즌별 기록이 담겨있는 csv 파일을 로드한다.
from langchain.schema import Document
documents = []
for name in df['이름'].unique():
document = f"{name} 선수에 관한 문서입니다. \n"
for idx, row in df[df['이름'] == name].iterrows():
document += str(row.to_dict())[1:-1]
document += '\n'
documents.append(Document(page_content=document))- 데이터베이스에 저장하기 위해 전처리를 진행한다.
- langchain에 맞는 Document 형태로 변환한다.
- 각 문서를 이름별로 분류하여 저장한다.
Cohere API Authentication
from getpass import getpass
cohere_api_key = getpass()
- Cohere API 키 입력
SAVE DB
from langchain.embeddings import CohereEmbeddings
from langchain.vectorstores import Qdrant
embeddings = CohereEmbeddings(model="embed-multilingual-light-v3.0", cohere_api_key=cohere_api_key)
db = Qdrant.from_documents(
documents,
embeddings,
path="/tmp/local_qdrant",
collection_name="my_documents",
)- embed-multilingual-light-v3.0 모델을 활용하여 임베딩을 생성한다.
- 한국어가 지원되는 모델을 선택해야 하므로 multilingual 모델을 선택하였다.
- Qdrant DB에 데이터를 저장한다.
Practice
1. Simple LCEL Practice
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 템플릿
template = '''아래 글의 내용을 참고해서 질문에 대한 답을 해줘.
{context}
질문: {question}
답변:
'''
retriever = db.as_retriever(search_type="mmr", search_kwargs={"k": 1})
# 프롬프트 템플릿 생성
prompt = PromptTemplate(template=template, input_variables=["question", "context"])
# LLM Chain 객체 생성
hitter_detail_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
- template: 원하는 형태에 맞춰 템플릿을 작성한다.
- retriever: 앞서 저장한 db를 활용하여 retriever를 생성한다.
- search_type: maximum marginal relevance search를 활용한다.
- search_kwargs={"k": 1}로 설정하여 가장 관련있는 하나의 문서만 가져온다.
- prompt: 템플릿에 맞추어 프롬프트를 생성한다.
- hitter_detail_chain: LLM Chain 객체를 생성한다.
Example
question = "손아섭의 2014년 홈런 개수는?"
hitter_detail_chain.invoke(question) 손아섭의 2014년 홈런 개수는 18개입니다.
question = "손아섭의 2010년 기록을 알려줘"
hitter_detail_chain.invoke(question) 손아섭의 2010년 기록은 다음과 같습니다.
- 소속팀: 롯데 자이언츠
- 포지션: LF
- 타율: 0.306
- 홈런: 11개
- 타점: 47개
- 도루: 6개
- WAR: 2.85
question = "호세가 출루율 0.5를 넘었던 시즌은?"
hitter_detail_chain.invoke(question) 호세가 출루율 0.5를 넘었던 시즌은 2001년입니다.
question = "아두치가 20-20을 달성한 시즌은?"
hitter_detail_chain.invoke(question) 아두치가 20-20을 달성한 시즌은 2015년입니다.
question = "테임즈가 40-40을 달성한 시즌은? 기록과 함께 알려줘. 그리고 40-40의 의미는 뭐야?"
hitter_detail_chain.invoke(question) 테임즈가 40-40을 달성한 시즌은 2015 시즌이다. 이 시즌에 테임즈는 47개의 홈런과 40개의 도루를 기록했다.
40-40은 한 시즌에 40개 이상의 홈런과 40개 이상의 도루를 기록하는 것을 말한다. 이는 매우 어려운 기록으로, 메이저 리그 역사상 40-40을 달성한 선수는 4명 뿐이다. 테임즈는 KBO 역사상 최초로 40-40을 달성한 선수이다.
- 20-20이나 40-40에 대해서도 이해하고 대답한다.
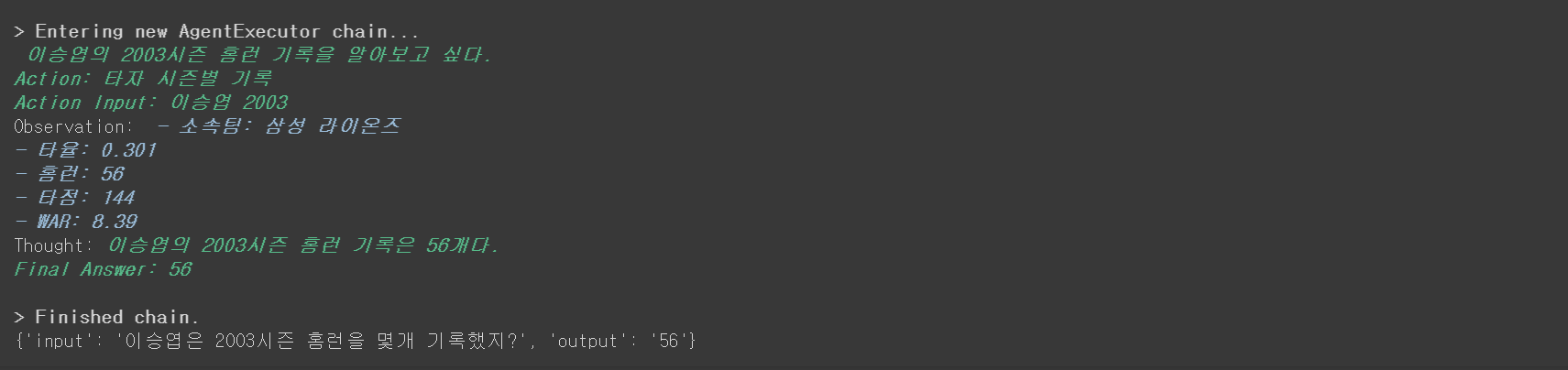
question = "이승엽이 홈런을 가장 많이 친 시즌은?"
hitter_detail_chain.invoke(question) 이승엽이 홈런을 가장 많이 친 시즌은 2003년으로, 56개의 홈런을 기록했습니다.
question = "문규현은 원클럽맨이니? 그 이유는?"
hitter_detail_chain.invoke(question) 문규현은 원클럽맨입니다. 그는 2002년부터 2019년까지 롯데 자이언츠에서만 뛰었습니다.
question = "손아섭은 KBO에서 원클럽맨이니? 그 이유는?"
hitter_detail_chain.invoke(question) 손아섭은 KBO에서 원클럽맨이 아닙니다. 그는 2022년에 NC 다이노스로 이적했습니다.
question = "안치홍이 뛰었던 팀들을 얘기해줄래?"
hitter_detail_chain.invoke(question) 안치홍이 뛰었던 팀은 다음과 같습니다.
- KIA 타이거즈
- 롯데 자이언츠
question = "안치홍의 주 포지션은 어디야?"
hitter_detail_chain.invoke(question) 안치홍의 주 포지션은 2루수입니다.
확실히 주어진 데이터들을 기반으로 여러가지 대답을 잘 생성해내고 있다.
question = "이대호에 대해 알려줄래?"
hitter_detail_chain.invoke(question) 이대호는 1982년 6월 22일생으로, 롯데 자이언츠에서 뛰는 야구 선수입니다.
2001년에 프로에 데뷔하여 2022년까지 롯데 자이언츠에서만 뛰고 있습니다.
주로 1루수와 지명타자로 활약했으며, 2010년에는 홈런왕과 타점왕을 차지하기도 했습니다.
이대호는 통산 2,500안타를 달성한 역대 11번째 선수이며,
2017년에는 월드 베이스볼 클래식에 국가대표로 출전하기도 했습니다.
question = "이승엽은 누구야?"
hitter_detail_chain.invoke(question)질문: 이승엽은 누구야?
답변:
이승엽은 전 KBO 리그 삼성 라이온즈의 야구 선수입니다.
그는 1995년부터 2017년까지 프로 야구 선수로 활약했습니다.
그는 1998년과 2003년에 홈런왕을 차지했고, 2003년에는 타점왕을 차지했습니다.
그는 2006년에 두산 베어스로 이적했지만, 2012년에 삼성 라이온즈로 복귀했습니다.
그는 2017년에 은퇴했습니다.
세세한 기록들보다는 인물에 대해 물어보기 때문에 어느정도 거짓들이 섞여서 나오는 모습이다. 해당정보들을 DB에 더 추가하는 방법도 있지만, 간단하게 Agent를 활용하여 보완해보자.
2. Simple Agent Practice
Agent를 활용하면 Agent가 사용할 도구를 선택할 수 있게 할 수 있다. 위처럼 선수에 대한 간략한 정보를 얻고 싶다면 위키피디아 체인을 활용하고, 시즌에 대한 세세한 기록이 궁금하다면 hitter_detail_chain을 활용하는 식이다.
from langchain.retrievers import WikipediaRetriever
retriever = WikipediaRetriever(lang='ko', search_type="mmr")
# LLM Chain 객체 생성
wiki_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| VertexAI(model_name="text-bison", max_output_tokens=1024, temperature=0.9)
| StrOutputParser()
)- 위키피디아 체인을 생성한다.
- temperature를 좀 더 높게 설정하여 풍부한 표현이 가능하도록 한다.
from langchain.agents import Tool
tools = [
Tool(
name="타자 시즌별 기록",
func=hitter_detail_chain.invoke,
description="해당 타자의 시즌별 기록을 알아볼 때 유용합니다.",
),
Tool.from_function(
name="위키피디아",
func= wiki_chain.invoke,
description="해당 타자의 전반적인 정보를 알고 싶을 때 유용합니다."
)
]- agent를 구성할 수 있도록 tool 리스트를 생성한다.
- 각각 원하는 상황에 쓰일 수 있도록 description을 추가한다.
from langchain.agents import AgentType, initialize_agent
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)- agent를 구성한다.
Example
agent.invoke(
{
"input": "이대호가 누구야?"
}
)
agent.invoke(
{
"input": "이승엽은 2003시즌 홈런을 몇개 기록했지?"
}
)
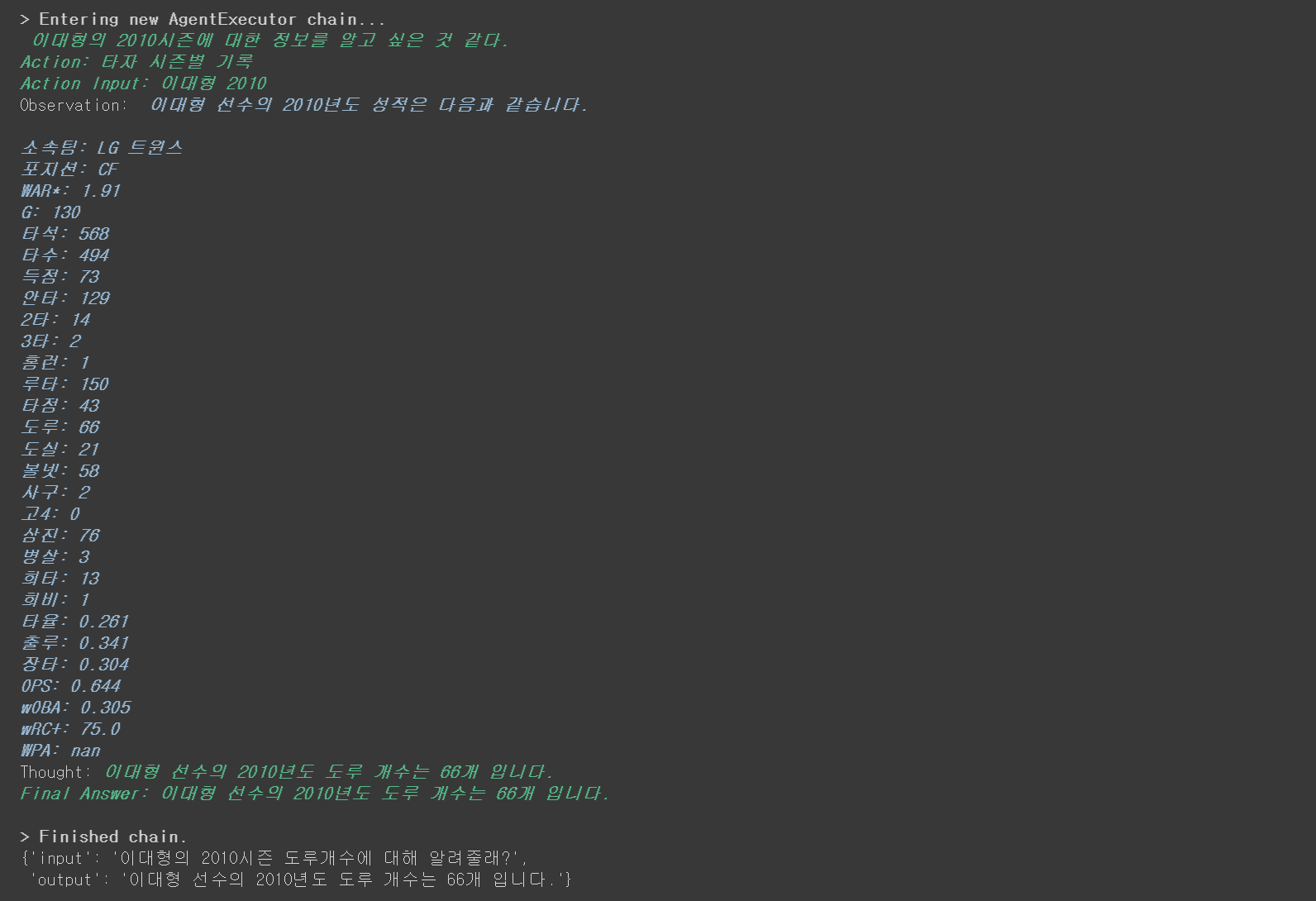
question = "이대형의 2010시즌 도루개수에 대해 알려줄래?"
agent.invoke(
{
"input": question
}
)
Repository
Reference
'프로젝트' 카테고리의 다른 글
| KBO 타자 대시보드 시각화 프로젝트 (1) | 2023.12.02 |
|---|---|
| 2023 KBO 선발투수 HEATMAP 시각화 프로젝트 (2) - 시각화 (2) | 2023.11.20 |
| 2023 KBO 선발투수 HEATMAP 시각화 프로젝트 (1) - 데이터 크롤링 및 전처리 (1) | 2023.11.14 |
| [프로젝트] numpy, pandas로 신경망 구현하여 프로야구 순위 예측하기 (0) | 2022.07.19 |