
시작하기 앞서...
2023 프로야구가 어제 LG 트윈스의 우승으로 끝났다. (롯데는 언제쯤...) 기념으로 간단히 10구단의 대표 투수들을 임의로 선정해서 각 이닝별 실점에 관련된 히트맵을 태블로로 시각화하는 프로젝트를 진행하려고 한다.
진행 단계는 다음과 같다.
1. 데이터 크롤링 및 전처리
selenium, pandas 등을 활용하여 스탯티즈와 kbo사이트 등을 통해 원하는 데이터를 크롤링한다. 그 후, 크롤링 과정에서 데이터를 시각화하고자 하는 데이터로 전처리한다.
kbo 사이트를 통해 경기별 데이터를 크롤링했고 이닝별 실점과 같은 좀 더 구체적인 데이터를 얻을 수 없어서 스탯티즈 사이트를 통해 추가적으로 데이터를 크롤링하고 전처리를 진행하였다.
2. 태블로로 시각화하기
태블로를 활용하여 히트맵을 시각화한다. 링크를 참고하여 작성하였다. 대충 아래와 같은 느낌...

10월동안 태블로에 대해 공부했었고 이번 프로젝트를 통해 간단한 시각화를 진행하고 앞으로도 종종 시각화 연습을 하고자 한다.
KBO 사이트 크롤링
1. Import Library
import pandas as pd
from selenium import webdriver
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.by import By
import time- pandas 라이브러리는 데이터프레임을 다루기 위함이다.
- read_html을 통해 데이터를 손쉽게 크롤링할 수 있다.
- 기존에는 BeautifulSoup과 같은 라이브러리를 고려했지만, 이 방법이 더 간편하여 사용하였다.
- to_csv를 통해 데이터프레임을 csv 파일 형태로 저장한다.
- read_html을 통해 데이터를 손쉽게 크롤링할 수 있다.
- selenium 라이브러리를 통해 동적으로 웹크롤링이 가능하다. (원하는 버튼 클릭 및 검색 등)
- Select와 By 모두 동적 크롤링을 위해 사용한다.
- time을 통해 sleep으로 request 관련 에러를 방지한다.
2. Data Crawling
columns = ["선수명", "날짜", "상대", "구분", "결과", "ERA1", "TBF", "IP", "H", "HR", "BB", "HBP", "SO", "R", "ER", "ERA2"]
df = pd.DataFrame(columns = columns)
players = [("페디", 53913), ("안우진", 68341), ("뷰캐넌", 50404), ("알칸타라", 69045), ("임찬규", 61101), ("문동주", 52701), ("이의리", 51648), ("고영표", 64001), ("김광현", 77829), ("반즈", 52528)]
driver = webdriver.Chrome()
- 미리 설정해둔 Column에 맞추어 데이터프레임을 설정한다.
- 임의로 선정한 선수명 그리고 그에 해당하는 player id를 튜플 형식으로 리스트로 저장한다.
- 10명으로 선수를 제한했기에 이렇게 해도 가능했지만, 만약에 100명, 200명이 된다면?
- 좀 더 동적으로 선수명만 가지고 검색을 한다던가 하는 방식으로 해결해야 할 것임.
- selenium의 webdriver를 활용하여 크롬 브라우저를 킨다.
for player, player_id in players:
url = 'https://www.koreabaseball.com/Record/Player/PitcherDetail/Daily.aspx?playerId='+str(player_id)
driver.get(url)
time.sleep(3)
select = Select(driver.find_element(By.ID, 'cphContents_cphContents_cphContents_ddlSeries'))
select.select_by_visible_text('KBO 정규시즌')
time.sleep(1)
page_source = driver.page_source
tables = pd.read_html(page_source)
for table in tables:
table.rename(columns={table.columns[0] : "날짜"}, inplace=True)
table.drop(len(table)-1, axis=0, inplace=True)
table.insert(0, '선수명', player)
df = pd.concat([df, table])- for 문 형태로 선수별로 진행한다.
- driver에 해당 url을 get으로 전달한다.
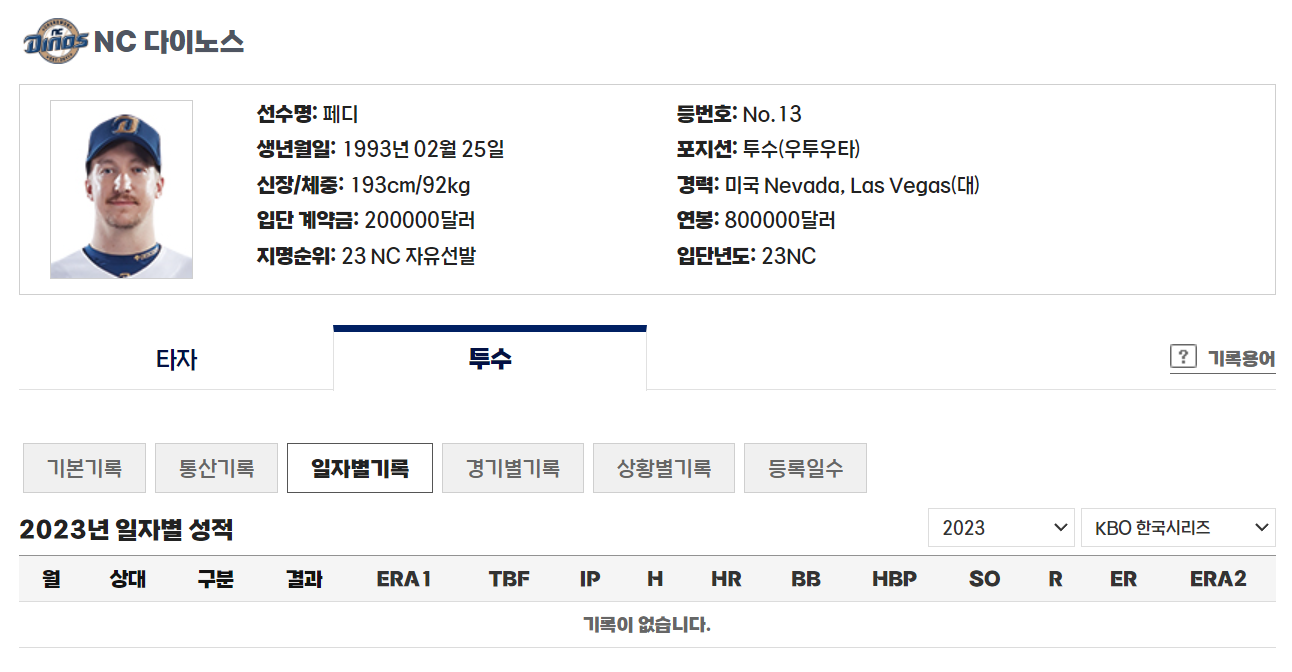
- 처음에는 기록이 없다고 나온다. 이는 카테고리가 "KBO 한국시리즈로 되어있기 때문이다. 따라서 select를 통해 "KBO 정규시즌"을 선택해주어야 한다.
- find_element에 해당하는 드롭다운의 ID를 전달한다. (F12를 통해 개발자 도구를 열고 소스를 찾다보면 해당하는 ID를 확인할 수 있다.)
- 그 후, select_by_visible_text를 통해 "KBO 정규시즌"을 선택한다.
- 그러면 다음 사진처럼 기록들이 아래에 나오게 된다.
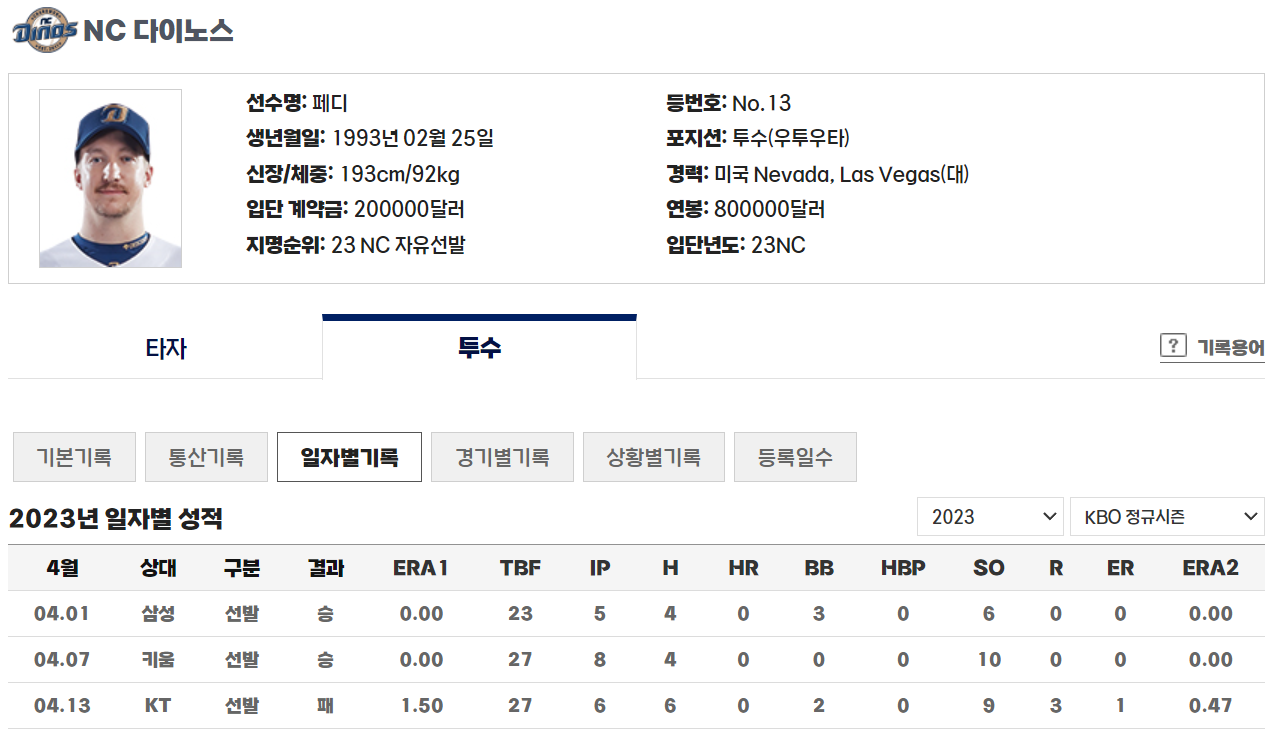
- 그리고 page_source를 pd.read_html에 전달해주면 해당하는 웹 페이지로부터 테이블을 추출하여 데이터프레임으로 저장이 된다.
- 그 후, 원하는 형태로 전처리를 진행하고 데이터 프레임화시키면 다음과 같이 데이터가 잘 뽑힌 것을 확인할 수 있다.

df.to_csv("pitcher_10_2023_daily.csv",index=False)- to_csv 함수를 활용하여 저장한다.
- index는 필요없으므로 False로 설정한다.
스탯티즈 사이트 크롤링
이대로 끝내면 좋겠지만... KBO에서 받은 데이터는 내가 원하는 데이터에 부족하다. 나는 투수들의 각 이닝별 실점에 대한 히트맵을 만들려고 한다. 따라서 각 이닝별 실점에 관한 데이터가 필요하다.
다만, 완전히 정리된 형태의 데이터는 찾기 힘들었다. 그래서 스탯티즈의 Playlog를 활용하여 원하는 형태의 데이터를 만들 것이다.

작업 순서는 다음과 같다.
1. 기존에 받은 KBO 데이터에서 원하는 선수의 '선발'로 뛴 날짜를 찾는다.
2. 해당 날짜를 위 스탯티즈 페이지에 검색하여 해당 날짜에 해당하는 기록을 받는다.
3. 야구 규칙에 의거하여 각 회별 실점을 계산하고 데이터에 저장한다.
1. Import Library
import pandas as pd
import time
from urllib.parse import quote
from collections import defaultdict
from tqdm import tqdm- pandas : 데이터프레임 처리
- time : sleep 함수 사용목적
- quote : URL에 한글을 그대로 전달하면 오류가 난다. 따라서 quote를 통해 퍼센트 인코딩을 하고 전달한다.
- defaultdict : 딕셔너리 형태로 데이터를 저장하고 데이터프레임화시킬 예정이다.
- tqdm : 크롤링 과정을 확인하기 위함
daily_df = pd.read_csv("./pitcher_10_2023_daily.csv")
players = [("페디", "1993-02-25", "NC"), ("안우진", "1999-08-30", "키움"), ("뷰캐넌", "1989-05-11", "삼성"), ("알칸타라", "1992-12-04", "두산"), ("임찬규", "1992-11-20", "LG"), ("문동주", "2003-12-23", "한화"), ("이의리", "2002-06-16", "KIA"), ("고영표", "1991-09-16", "KT"), ("김광현", "1988-07-22", "SSG"), ("반즈", "1995-10-01", "롯데")]
stadium_db = {"롯데": "부산사직야구장", "NC": "창원NC파크", "키움": "고척스카이돔", "삼성": "대구삼성라이온즈파크", "두산": "잠실야구장", "LG": "잠실야구장", "한화": "한화생명이글스파크", "KIA": "광주기아챔피언스필드", "KT": "수원KT위즈파크", "SSG": "인천SSG랜더스필드"}
db = defaultdict(list)- KBO 사이트에서 받은 데이터를 daily_df로 읽는다.
- (선수명, 생일, 소속팀)으로 된 튜플을 리스트화 시킨다.
- 각 구단별 야구장을 딕셔너리 형태로 저장한다.
- 데이터를 저장할 딕셔너리를 선언한다.
for player, birth, team in tqdm(players):
print(f"###### {player} 시작 ######")
# 선발인 경우만 저장
for idx, daily in daily_df[daily_df['선수명'] == player].iterrows():
if daily['구분'] != '선발':
continue
str_daily = str(daily['날짜']).split('.')
pdate = "2023-"+str_daily[0]+"-"+str_daily[1]
if len(str_daily[1]) == 1:
pdate += "0"
url = "http://www.statiz.co.kr/player.php?opt=6&name="+quote(player)+"&birth="+birth+"&re=1&da=1&year=2023&plist=&pdate="+pdate
tables = pd.read_html(url)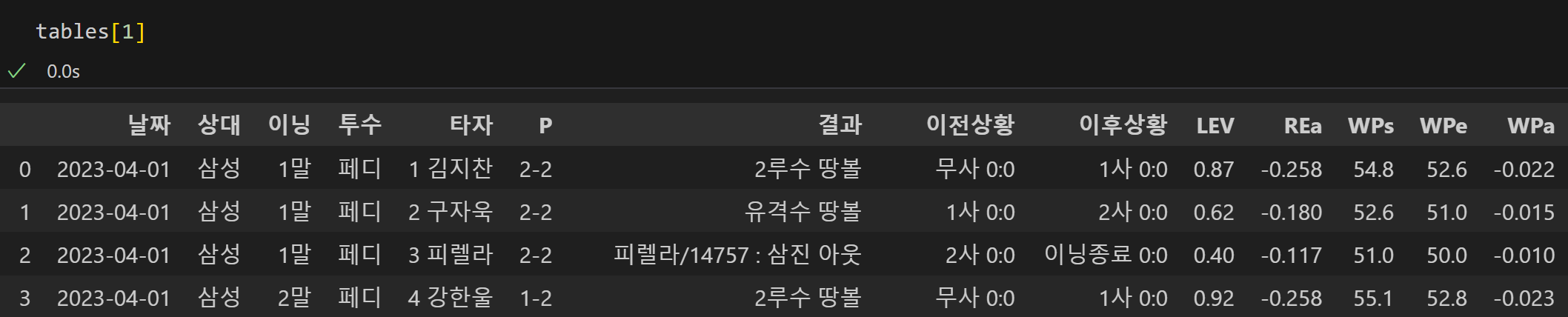
- 다운받고자 하는 선수별로 for문을 진행한다.
- kbo 사이트에서 받은 데이터를 for문으로 돌면서 선발이 아닌 경우는 continue로 진행하지 않는다. (ex. 불펜)
- 그리고 데이터에 있는 날짜를 원하는 형태로 바꾸어준다.
- kbo에서 받은 데이터는 4.01 혹은 4.3처럼 소수형태로 되어 있다.
- 따라서 10일, 20일, 30일같은 경우는 4.3처럼 되어 있어서 뒤에 "0"을 붙여준다.
- 매개변수(player, birth, pdate)를 추가하여 스트링 형태의 url을 만든다.
- pd.read_html을 활용하여 해당하는 데이터를 데이터프레임으로 변환시킨다.
- 그 결과로 위와 같은 형태로 데이터프레임이 생성된다.
start, end = False, False
score_1 = []
top_or_bottom = "초"
inning = 1
home_team, away_team = "", ""
score = 0
for idx, row in tables[1].iterrows():
# 초 공격인지 / 말 공격인지 체크 & 이닝 체크
if "초" in row['이닝']:
top_or_bottom = "초"
inning = int(row['이닝'][0])
else:
top_or_bottom = "말"
inning = int(row['이닝'][0])- start, end: 한이닝의 시작과 끝을 체크하기 위한 변수이다.
- score_1: 한이닝의 시작지점의 스코어를 저장하는 리스트이다.
- top_or_bottom: 그 이닝이 "초"인지 "말"인지 알려주는 변수이다.
- inning: 몇회인지 저장하는 변수
- home_team, away_team: 홈 & 어웨이 팀을 저장하는 변수
- score: 해당하는 이닝의 실점 수
- for 문을 통해 그 이닝이 몇회인지, 초인지 말인지를 저장한다.
# 이닝 시작과 끝을 체크하여 해당 이닝에 기록된 실점 반환
if start == False and '무사' in row['이전상황']:
start = True
score_1 = row['이전상황'].split(' ')[1].split(":")
# 한이닝을 온전히 던진 경우
if end == False and '이닝종료' in row['이후상황']:
start = False
end = True
score_2 = row['이후상황'].split(' ')[1].split(":")
if top_or_bottom == "초":
score = int(score_2[0]) - int(score_1[0])
home_team, away_team = team, row['상대']
else:
score = int(score_2[1]) - int(score_1[1])
home_team, away_team = row['상대'], team- 이제 이닝 시작과 끝을 체크하여 해당 이닝에 기록된 실점을 반환한다.
- "무사"가 처음으로 등장하면 이닝의 시작일 것이다.
- "이닝종료"가 끝에 등장하면 이닝의 끝일 것이다.
- 따라서 이닝 끝의 스코어와 이닝 시작의 스코어를 뺀 값을 score저장한다.
- 그와 함께 홈 팀과, 원정 팀에 대한 정보도 같이 저장한다.
# 강판 당한 경우
elif idx == len(tables[1])-1:
end = True
score_2 = row['이후상황'].split(' ')[-1].split(":")
if top_or_bottom == "초":
score = int(score_2[0]) - int(score_1[0])
home_team, away_team = team, row['상대']
else:
score = int(score_2[1]) - int(score_1[1])
home_team, away_team = row['상대'], team
# 승계주자 있는 경우만 처리
if len(row['이후상황'].split(' ')):
runners = 0
# 승계주자 몇명인지 체크
if row['이후상황'].split(' ')[1] == '만루':
runners = 3
else:
runners = len(row['이후상황'].split(','))
# 승계주자 실점했는지 체크
url_2 = "http://www.statiz.co.kr/boxscore.php?opt=1&sopt=0&date="+pdate
match_data = pd.read_html(url_2)[1:]
tables_2 = pd.DataFrame()
for idx, data in enumerate(match_data):
if home_team in list(match_data[idx]['팀']):
tables_2 = data
break
if top_or_bottom == '초':
score_3 = int(tables_2.iloc[0][str(inning)].split(' ')[0])
score += min(score_3-score, runners)
else:
score_3 = int(tables_2.iloc[1][str(inning)].split(' ')[0])
score += min(score_3-score, runners)- 투수가 항상 이닝이 끝날 때까지 던질 수는 없다. 따라서, 중간에 강판당하는 경우도 고려해야 한다.
- 강판당한 경우는 이닝종료가 없으면서 테이블의 마지막 행에 해당하는 데이터들일 것이다.
- 이닝 종료까지 던졌을 때와 마찬가지로 실점을 계산한다.
- 그 후, 승계주자에 대한 처리를 해야 한다.
- 우선 승계주자의 수를 runners에 담는다.
- 그리고 해당 경기 회별로 스코어가 담긴 사이트 링크에서 해당하는 이닝에 나온 점수를 가져온다.
- 원래는 해당 경기만 해당하는 "경기요약" 페이지를 활용하려고 했는데... 삼성 구단 홈구장에 대한 데이터가 누락되어 있어서 해당하는 날짜에 모든 경기를 조회했다.
- 해당하는 경기에 대한 정보를 tables_2에 저장한다.
- 그리고 이닝과 초,말에 따라 해당하는 점수를 가져온다.
- 이제 승계 주자가 들어온만큼 기존 실점값에 더해주어야 한다.
- 이는 간단하다.
- 실제 실점에서 기존 실점을 뺀 값이 승계 주자 수보다 크다면 승계 주자가 모두 들어왔다는 뜻이고, 반대라면 그만큼 승계 주자가 들어왔다는 뜻이다.
- 따라서 min 함수를 통해 기존 실점값에 들어온 승계 주자 수를 더해준다.
# db에 저장
if end == True:
db['날짜'].append(row['날짜'])
db['상대'].append(row['상대'])
db['이닝'].append(inning)
db['투수'].append(player)
db['실점'].append(score)
db['Home Team'].append(home_team)
db['Away Team'].append(away_team)
db['구장'].append(stadium_db[home_team])
end = False
time.sleep(10)- db에 원하는 정보들을 append해준다.
- request관련 에러가 발생하지 않도록 sleep을 해준다.
df = pd.DataFrame.from_dict(db)
df.head()
- db를 데이터프레임으로 바꾸고, head로 확인하면 데이터가 원하는 형태로 완성된 모습을 볼 수 있다.
df.to_csv("pitcher_10_2023_daily_detail_2023_11_14.csv",index=False, na_rep='NaN')- 이제 to_csv 함수를 통해 csv파일로 변환하면 끝!
'프로젝트' 카테고리의 다른 글
| ChatGPT에게 야구 지식 가르쳐주기 (1) - LangChain을 활용하여 RAG 구성하기 (0) | 2023.12.23 |
|---|---|
| KBO 타자 대시보드 시각화 프로젝트 (1) | 2023.12.02 |
| 2023 KBO 선발투수 HEATMAP 시각화 프로젝트 (2) - 시각화 (2) | 2023.11.20 |
| [프로젝트] numpy, pandas로 신경망 구현하여 프로야구 순위 예측하기 (0) | 2022.07.19 |