![[프로젝트] numpy, pandas로 신경망 구현하여 프로야구 순위 예측하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbun6yY%2FbtrHEArpt0c%2Fu2QaAWSDKtSW3FxBXMedWK%2Fimg.png)
1. 들어가기전에
내 코딩실력에 환멸을 느껴서, 가벼운 프로젝트부터 진행하고자 했다. 우선 해당 글을 참고하여 신경망을 스크래치로 구현하기로 마음먹었다. 그렇다면, 좀 더 흥미로운 주제를 하면 재밌을것 같아서 스탯티즈를 참고하여 각팀의 타율, 출루율, 장타율, 방어율, FIP, WHIP를 활용하여 프로야구 순위를 예측하는 프로그램을 만들기로 했다.
2. 뉴럴 네트워크 구성

위와 같이 뉴럴 네트워크를 구성하였다. 인풋 레이어와 히든 레이어 2개를 거치고 softmax 연산을 통해 최종 확률을 계산하게 된다. loss function은 cross entrophy를 사용하였고, activation function은 sigmoid를 사용하였다.
3. 코드 살펴보기
3가지 파일로 구성된다.
- main.py: 메인 로직을 수행
- data_preprocessing.py: 데이터 전처리를 수행
- neural_network.py: 신경망이 클래스로 구현되어 있음
main.py와 data_preprocessing.py는 특이사항이 없으니 neural_network.py만 line by line으로 보도록 한다. (자세한 사항은 깃허브로)
필요한 라이브러리 import (1 ~ 4)
import numpy as np
import pandas as pd
from collections import defaultdict
from tqdm import tqdm
사용될 함수 구현 (5 ~ 18)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def deriv_sigmoid(x):
fx = sigmoid(x)
return fx * (1 - fx)
def softmax(z):
exp_z = np.exp(z)
sum_exp_z = np.sum(exp_z)
return exp_z / sum_exp_z
def ce_loss(y_true, y_pred):
return -(y_true * np.log(y_pred + 10**-100) + (1-y_true) * np.log(1 - y_pred + 10**-100))ce_loss같은 경우 참고하던 코드에 10**-100가 있어서 그대로 사용하였다. y_pred가 0일 때 무한대가 되지 않기 위함인듯 하다.
클래스 구현 및 변수 초기화 (20 ~ 27)
class neuralnetwork:
def __init__(self):
self.w1 = np.random.rand(6, 5)
self.w2 = np.random.rand(5, 5)
self.w3 = np.random.rand(5, 10)
self.b1 = np.random.rand(5)
self.b2 = np.random.rand(5)
self.b3 = np.random.rand(10)xavier initialization 구현 (29 ~ 32)
def xavier_initialization(self):
self.w1 = np.random.randn(6, 5) / np.sqrt(1/6)
self.w2 = np.random.randn(5, 5) / np.sqrt(1/5)
self.w3 = np.random.randn(5, 10) / np.sqrt(1/5)실험을 위해서 xavier initialization을 구현해보았다. 데이터때문인지 큰 차이는 느끼지 못했다.
train 함수 (34 ~ 77)
def train(self, X, y, lr, epochs):
output = defaultdict(list)
for epoch in tqdm(range(epochs)):
total_loss = 0
for idx in range(len(X)):
# 순전파
# 계산
inp = np.array(X.iloc[idx])
h1 = inp.dot(self.w1) + self.b1
h2 = sigmoid(h1).dot(self.w2) + self.b2
o = h2.dot(self.w3) + self.b3
y_pred = softmax(o)
y_true = np.zeros(10)
y_true[int(y.iloc[idx])-1] = 1
loss = ce_loss(y_true, y_pred)
total_loss += np.sum(loss)
# 역전파
# b3 & w3 역전파
de_dz3 = y_pred-y_true
deriv_3 = np.reshape(h2, (len(h2), 1)) * de_dz3
# b2 & w2 역전파
de_dz2 = self.w3.dot(np.reshape(de_dz3, (len(de_dz3), 1)))
de_dz2 = de_dz2.squeeze()
deriv_2 = np.reshape(h1, (len(h1), 1)) * (de_dz2 * deriv_sigmoid(h2))
# b1 & w1 역전파
de_dz1 = self.w2.dot(np.reshape(de_dz2, (len(de_dz2), 1)))
de_dz1 = de_dz1.squeeze()
deriv_1 = np.reshape(inp, (len(inp), 1)) * (de_dz1 * deriv_sigmoid(h1))
# 업데이트
self.w3 -= lr*deriv_3
self.b3 -= lr*(de_dz3)
self.w2 -= lr*deriv_2
self.b2 -= lr*(de_dz2)
self.w1 -= lr*deriv_1
self.b1 -= lr*(de_dz1)
output['loss'].append(total_loss/len(X))
output['epoch'].append(epoch+1)
return pd.DataFrame(output)학습에 활용될 데이터인 X, y와 lr, epoch를 변수로 받는다. 주어진 epoch마다 순전파와 역전파를 반복하게 된다. epoch마다 loss값을 저장하여 데이터프레임 형태로 반환하게 된다.
predict 함수 (80 ~ 101)
def predict(self, X, y, **kwargs):
pred_top3 = defaultdict(list)
pred_detail = defaultdict(list)
for idx in range(len(X)):
inp = np.array(X.iloc[idx])
h1 = inp.dot(self.w1) + self.b1
h2 = sigmoid(h1).dot(self.w2) + self.b2
o = h2.dot(self.w3) + self.b3
y_pred = softmax(o)
sort_y_pred = y_pred.argsort()[::-1][:3]
sort_y_pred += 1
TEAM = kwargs["TEAM"].iloc[idx]
pred_top3[TEAM] = sort_y_pred
pred_detail[TEAM] = y_pred
pred_top3 = pd.DataFrame(pred_top3)
pred_detail = pd.DataFrame(pred_detail)
pred_top3.index = range(1, 4)
pred_detail.index = range(1, 11)
return pred_top3, pred_detail주어진 데이터에 대해 순전파를 진행하고 argsort()를 활용하여 가장 큰 확률순대로 정렬하고 각팀별 예측 등수 top3와 각팀별 예측되는 등수의 확률을 반환한다.
4. 결과
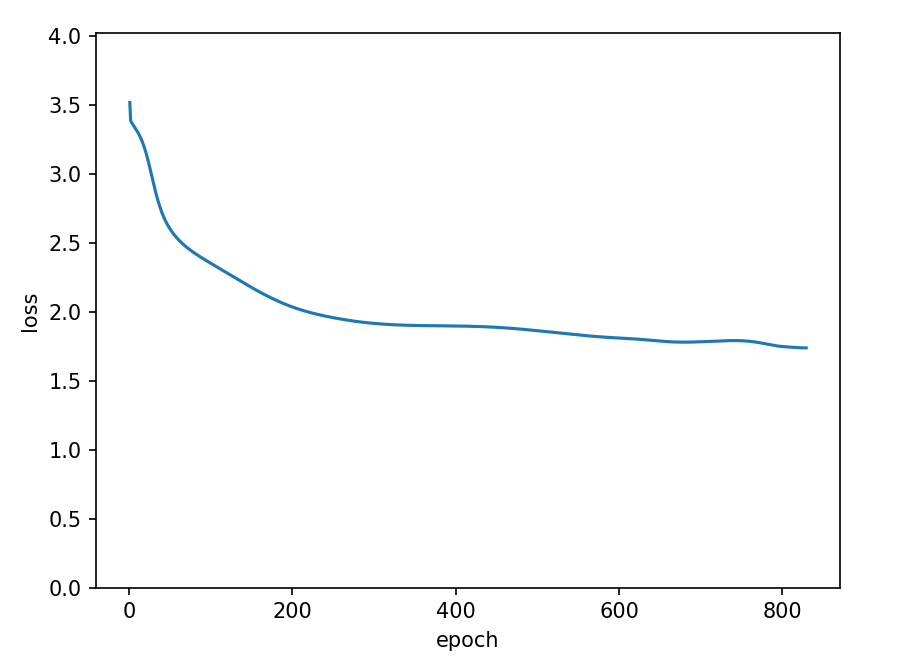
loss값이 줄어드는걸 보아, 학습이 진행되는 것은 확인할 수 있었지만 그리 학습이 잘되었다고 보기는 힘들것같다. 아마 데이터에 대한 문제가 컸을 것이다.

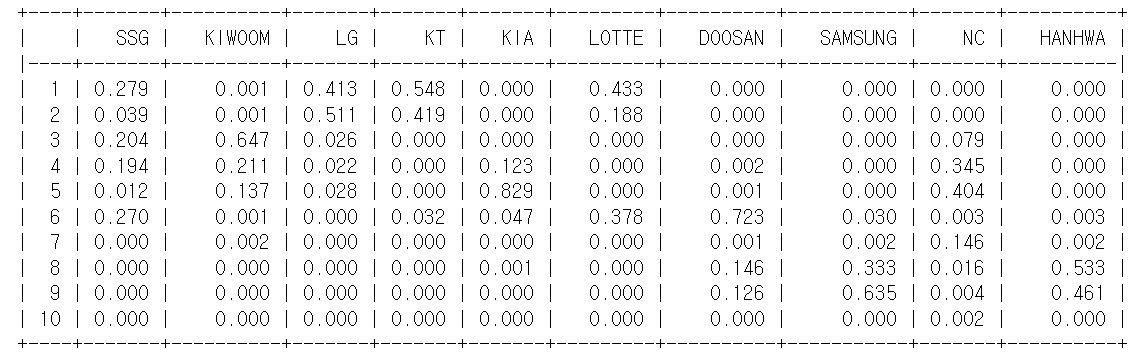
완성된 모델에 올시즌 전반기까지의 데이터를 넣어보면 위와 같은 결과가 나오게 된다. 칼럼의 순서는 현재(2022년 7월 19일 기준) 순위 순서대로 이다. 대체로 현재 순위와 비슷하게 형성된다. 현재 순위 순서대로 각팀별로 짧게 분석을 해보겠다.
1위) SSG 랜더스

부동의 1위팀답게 1위 확률이 높게 나왔고 가을야구권에 형성되어 있다.
2위) 키움 히어로즈

우승까지는 힘들지만, 가을야구는 무조건 간다고 예상된다. (실제로도 우승 기록은 없지만 가을야구는 꾸준히 가는 팀이다.)
3위) LG 트윈스
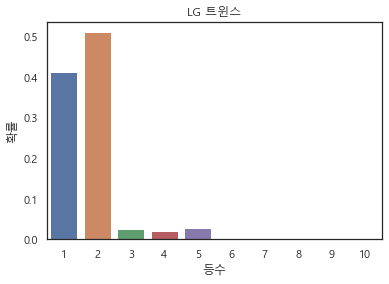
LG도 수치상으로는 정말 강팀이다. 최근 전력이 많이 올라왔고 투타밸런스가 좋다. (이러다 롯데보다 먼저 우승하는게 아닐까...)
4위) KT 위즈
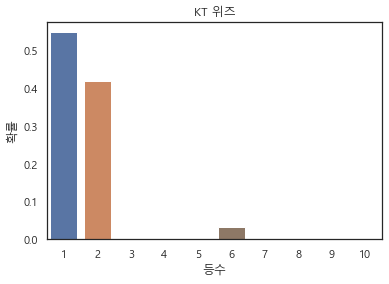
작년 우승팀답게 우승확률이 높게 예측되었다. 현재의 등수는 시즌 초반때문 인듯하다. 시즌 초반 부상이나 용병 문제 때문에 하위권에 쳐져있다가 최근들어 놀라운 기세로 4위까지 올라왔다. 확실히 전력 자체는 좋은 팀인듯 하다.
5위) 기아 타이거즈

현재 등수와 예측 등수가 같고 확률이 80%가 넘는다. 나성범 영입 효과와 더불어, 소크라테스 등 여러 타자들의 활약속에 상위권에 올라갔다가 용병 투수들의 아쉬운 활약속에 무너진 선발진이 버티지 못해 최근 연패를 거듭했다. 하위권 전력은 아니지만, 상위권도 힘든 전력이라고 생각된다.
6위) 롯데 자이언츠
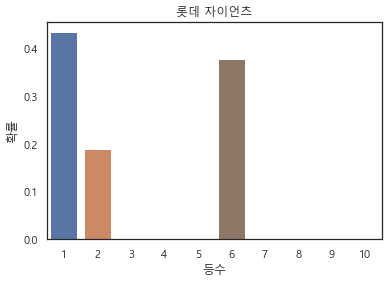
loss값이 높은 이유가 있었다. 억지로 분석을 해보자면, 보이는 지표에 비해서 항상 세밀한 플레이(수비와 주루 등)이 부족한 팀이라서 성적이 나오지 않는다고 생각된다. 이대호 선수의 은퇴시즌인데...가을야구는 가자...
7위) 두산 베어스

항상 가을야구는 가던 강팀이었지만, 올해는 쉽지 않다.
8위) 삼성 라이온즈

현재 창단 최다인 11연패를 기록하고 있는 팀이다. (2022년 7월 19일 기준) 확실히 낮은 등수가 예측되었다. 작년 최고 승률팀의 몰락이다. 한편, 연패 기간동안 100실점을 넘게 줬으니 방어율과 같은 투수관련 지표가 크게 올랐고 이것이 예측하는데 영향이 컸을 것이다.
9위) NC 다이노스

9위 팀치고 높은 등수가 예측된다. 시즌 개막전 많은 전문가들이 가을야구는 갈 것이라고 예측된 팀이기도 하고 루친스키와 구창모라는 필승 선발 투수덕분에 좋아진 투수지표의 영향이 크다고 생각된다. 시즌 초반 여러 이슈로 인해, 많은 패배를 기록해서 아직 9위에 위치한 듯하다.
10위) 한화 이글스

부동의 약팀이다. 모든 지표에서 낙제점에 가까운 지표를 지니고 있었으며 이는 그래프에서 드러난다. 데이터의 부족과 dependency문제때문에 10등이 안나왔다고 생각된다.
5. 회고 및 아쉬운 점
5-1. 회고
제대로 안다고 생각했지만, 막상 구현하려니 힘들었다. (사실 제대로 구현했는지도 잘 모르겠다.) 순전파와 역전파 과정에서 2차원 배열로된 numpy 연산을 구현하는데 애를 많이 먹었다.
조그만 것이라도 만들었다는 생각을 얻어간다. 그리고 앞으로는 프로젝트의 복잡도를 늘려가자. 기회되면 도커나 aws를 사용해서 서빙까지 해보려했는데, 그러기엔 너무 작고 소중한 프로젝트기에 다음으로 미룬다..!
좋은 라이브러리나 프레임워크들이 많다. 구현해주신 분들께 항상 감사하며 사용하자!
5-2. 아쉬운 점
데이터 dependency 문제
상관계수에 대한 공부를 하던 중 데이터간 종속성이 높으면 학습에 악영향을 미치고 다중공선성 문제를 야기한다는 점을 알게되었다. (회귀문제이든 분류문제이든 항상 걱정해야 한다.)
그리고 프로젝트의 독립변수(인풋 데이터)에 대해 생각해봤을 때, 타율과 출루율 그리고 방어율과 whip 등은 종속성이 높지 않을까 예측을 하였고 상관계수 분석을 해보았다.
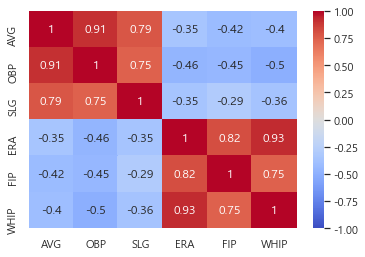
그 결과, 타율(AVG)와 출루율(OBP)는 0.91로 상당히 높은 수치를 기록했고 방어율(ERA)와 WHIP(이닝당 출루허용율) 또한 0.93으로 높았다. 그리고 타격 지표끼리, 투수 지표끼리 양의 상관관계를 지니게 된다.
아마 학습이 잘안되었던 것은 데이터 자체의 부족뿐만 아니라 이러한 문제도 있었던 것 같다. 다른 머신러닝 프로젝트를 진행할 때에는 이 부분을 고려하자.
순위 예측 문제
각 팀마다 순위를 예측할 수 있게 하였는데, 이보다 나아가 전체 순위를 예측하기 위해서는 어떻게 구성해야할까? 지금 상태로는 각 등수에 대해 가중치를 주어 합치고 각 팀별 점수대로 순위를 매기는 방식이 떠오른다. 하지만, 아마 더 정확한 순위를 위해서는 좀 더 다른 방법을 고안해야할듯 하다.
6. 관련 링크
6-1. 깃허브 링크
6-2. Reference
- https://towardsdatascience.com/deriving-backpropagation-with-cross-entropy-loss-d24811edeaf9
- https://www.mldawn.com/back-propagation-with-cross-entropy-and-softmax/
역전파 구현에 있어서 도움을 많이 받은 글들이다. 특히, cross entropy와 softmax의 미분에 도움되었다.
'프로젝트' 카테고리의 다른 글
| ChatGPT에게 야구 지식 가르쳐주기 (1) - LangChain을 활용하여 RAG 구성하기 (0) | 2023.12.23 |
|---|---|
| KBO 타자 대시보드 시각화 프로젝트 (1) | 2023.12.02 |
| 2023 KBO 선발투수 HEATMAP 시각화 프로젝트 (2) - 시각화 (2) | 2023.11.20 |
| 2023 KBO 선발투수 HEATMAP 시각화 프로젝트 (1) - 데이터 크롤링 및 전처리 (1) | 2023.11.14 |